I have been noticing that there is some sort of confusion going around when it comes to AMD’s new 7nm GPU architecture. This is because some people are getting confused that whether they should call the new architecture RDNA or Navi, and which is which? Well, the short answer is that both RDNA and Navi are associated with AMD’s new 7nm GPUs and here I am going to clear all the doubts regarding them.
Technically, there are two types or levels of architecture that are used in the chip design, whether it is a CPU or GPU. The first is the ISA or Instruction Set Architecture and the second is the Microarchitecture. ISA or Instruction Set Architecture consists of the commands, operations, instructions, and instructions set. It acts as an interface between the hardware and the driver or software. The ISA defines the type of instructions supported by the processor (arithmetic/logic/branch/load/jump), the maximum length of the instructions (32-bit/64-bit), and the instruction format of each type of instruction (encoding schemes).
On the other hand, a micro-architecture is the implementation of the ISA in a particular design. It deals with concepts like pipelining, execution order of instructions, branching, etc. It should be noted that Processors with the same instruction set can have different microarchitectures. Here RDNA or GCN is the codename given for both the Instruction Set Architecture (ISA) and Microarchitecture for the AMD GPUs, while Polaris, Vega, and Navi are the Codenames for the series of GPU for these architectures. However, in general speaking, Polaris, Vega, and Navi may also be referred to as the GPU architecture by some people.
GCN vs RDNA Architecture
GCN stands for Graphics Core Next and is the architecture used by AMD for most of their graphics cards, right from the Oland, Cape Verde, Pitcairn, and Tahiti GPU chips to the modern-day Vega GPU chips. It has gone through various iterations and there is a total of five generations of the GCN architecture. Below, you can see the various GPUs that were based on the GCN architecture of various generations.
| GCN 1.0 | GCN 2.0 | GCN 3.0 | GCN 4.0 | GCN 5.0 | |
| GPU | Oland, Cape Verde, Pitcairn, Tahiti | Bonaire, Hawaii | Tonga (Volcanic Islands family), Fiji (Pirate Islands family) | Polaris 10, Polaris 11, Polaris 20, Polaris 21, Polaris 22, Polaris 30 | Vega 10, Vega 12, Vega 20 |
| APU | – | Temash, Kabini, Liverpool (in Playstation 4), Durango (in Xbox One and Xbox One S), Kaveri, Godavari, Mullins, Beema, Carrizo-L | Carrizo, Bristol Ridge, Stoney Ridge | – | Raven Ridge |
| Manufacturing Process | 28nm | 28nm | 28nm | 14nm / 12nm (Polaris 30) | 14nm / 7nm (Vega 20) |
Graphics Cards based on GCN 1.0, GCN 2.0 and GCN 3.0 architecture were built on the 28nm process, while the cards based on GCN 4.0 and GCN 5.0 architecture using 14nm process with the exception being Polaris 30 that uses 12nm, and Vega 20 with 7nm manufacturing process. Cards that use GCN 4.0 and GCN 5.0 are much more power-efficient and offer better performance over the older GCN generations (from 1st to 3rd). Also, all the GCN architecture-based graphics cards right from the GCN 1.0 use the PCIe 3.0 standard.
When it comes to memory, then all these GCN cards support GDDR5 memory right from the beginning, and the later generation GCN cards also include support for the HBM and HBM2 memory. HBM memory was introduced in the Fiji line of GPUs that include Radeon R9 FURY, Radeon R9 FURY Nano, Radeon R9 FURY X / X2, Radeon Instinct MI8, while the cards that use the more advanced HBM2 memory include Radeon RX Vega 56, Radeon RX Vega 64, Radeon VII, Radeon Instinct MI series cards.
RDNA or Radeon DNA is the successor of the GCN architecture and includes various improvements and a newer instruction set that makes it more efficient than GCN architecture. RDNA comes with new computer units and features a multilevel cache, improved rendering pipeline, working primitive shaders, updated display controller (Display Stream Compression 1.2a), and includes the support for GDDR6 memory. RDNA architecture is implemented on the 7nm FinFET manufacturing process on the GPUs. RDNA architecture supports the PCIe 4.0 bus interface that almost doubles the bandwidth offered by the PCIe 3.0.
RDNA vs Navi
Navi is the codename given to the series of GPUs that are built using the RDNA architecture on the 7nm FinFET manufacturing process. Sometimes, Navi and RDNA may be used interchangeably, and you may call Navi an architecture. The Radeon RX 5000 series Graphics cards are based on the RDNA architecture and use Navi GPUs. Both Radeon RX 5700 XT and Radeon RX 5700 use the same Navi 10 GPU but in different states. The RX 5700 uses the Navi 10 XL chip and the RX 5700 XT uses Navi 10 XT.
| RDNA 1.0 | |
| GPU | Navi 10, Navi 12 (more to come) |
| APU | – |
| Manufacturing Process | 7nm |
Major Differences between GCN and RDNA
In terms of technicality, the major architectural differences between GCN and RDNA architecture are as follows.
New Compute Units
The RDNA compute units are redesigned for improved single-threaded performance and offer better efficiency compared to the older GCN units. The IPC performance in RDNA is much higher at 1, which is around 0.25 in GCN, which can be experienced especially in gaming.
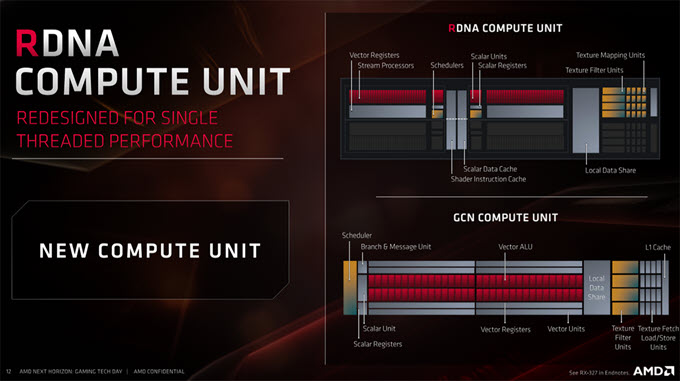
Single Cycle Instruction Issue
In GCN architecture, one instruction is issued every 4 cycles, but RDNA issues one instruction every 1 cycle, which is a more efficient way to handle simple instructions and it improves efficiency.
Wavefront Size (Wave32)
A wavefront is a fundamental group of work or a group of operations executed on a single SIMD. In GCN architecture the size of a wavefront is 64 threads (Wave64), but RDNA architecture supports the wavefront size of both 32 threads (Wave32) and 64 threads. The smaller size wavefront (Wave32) in RDNA helps in reducing clock cycles and improves single-threaded performance, especially in games.

Workgroup Processors (WGP)
In GCN, compute units (CU) forms the basic shader entity that contains ALUs, LDS, and memory access. In RDNA, the workgroup processor (WGP) forms the basic unit of shader hardware and one workgroup processor contains 2 compute units. This way more compute power and memory bandwidth can be directed to the single workgroup to enhance the performance.
1 WGP = 2 CU
WGP -> Workgroup Processor
CU -> Compute Unit
Multilevel Cache Hierarchy
RDNA has introduced a new L1 cache hierarchy that reduces the cache latency at each level, doubles the load bandwidth from L0 to ALU, and improves effective bandwidth. This also results in lower power consumption. Now, for the same power, 50% more work can be done which is a major improvement in performance.

Final Words
I hope that by the end of this article you have a pretty good understanding of the basic differences between RDNA, Navi, and GCN. However, if you still have some doubts then you can ask them in the comment section below. Also, if you have anything to add here or want to share your insight on this particular topic then you are very much welcome.
(*This post may contain affiliate links, which means I may receive a small commission if you choose to purchase through the links I provide (at no extra cost to you). Thank you for supporting the work I put into this site!)
![Failing Power Supply Symptoms [Top Signs of PSU Failure]](https://graphicscardhub.com/wp-content/uploads/2023/02/psu-failure-signs-211x150.jpg "Failing Power Supply Symptoms [Top Signs of PSU Failure]")

![Graphics Cards Slot Width Explained [Single, Dual, 2.2, 2.3, 2.5, 2.75]](https://graphicscardhub.com/wp-content/uploads/2019/09/graphics-card-slot-width-size-211x150.jpg "Graphics Cards Slot Width Explained [Single, Dual, 2.2, 2.3, 2.5, 2.75]")
Great read man. Why are people throwing the terms RDNA1 and RDNA 2? I am hearing that the next Playstation will have RDNA1 and the next Xbox is supposed to have RDNA2.. Have you heard that?
Well, the details of RDNA2 is not out yet but it could be just a small revision of the RDNA.
Akshat Gareth Jones here i have really enjoyed your site in fact bookmarked it. I would like to esquire were did you get all the info for the articles? I to am fascinated by pc’s
in general and have at least two boxes in-storage at the moment an old i5 and a slightly
younger i3 both out of order due ram problems.
Regards
Hello Gareth,
Thanks for the appreciation. Regarding articles, it is just a lot of reading, research and analyzing.
Hi, i want to build a ryzen 7 3700, aorus master but am confused by a site saying I need to upgrade to intel products. I surf the web, play solitair, songs, & word processing. My monitor is a freesync 1080p. My question is what are good gpu’s for my needs? I’m leaning towards Radeon RX 5700xt but they are soooo pricey.
I would say GTX 1650 SUPER should be enough for you even if you play some AAA games. Another option would be a Radeon RX 580 because you can get it cheaper.